
Did the 6-month pause on AI developments actually happen? Everything points to the fact that no-one in the field seriously considered to abide, but the wave of major releases at the end of September coincided with the end of the sixth month since the infamous open-letter. As if AI-companies and labs had informally put things on hold. With OpenAi's GPT4V (V for vision) now out in the open and ChatGPT with access to the internet, we are back on March-23 timeline.
Our tech-focused blog #NOT_TOO_FAST was not paused for that long, but it’s been 4 months since our last post. There is a lot to catch-up on, which will try to do in a structured way, and very likely over several posts.
We have not remained idle during all this time. We focused on building or preparing projects, putting to test the rhetoric that AI significantly enhances developers capabilities or, in our case, that AI could allow non-developers to build apps.
The most important of these projects was, to us, this website which we built the old-way : looking at documentations and debugging with Stack Overflow. We’ll take a minute to explain why we rebuilt it entirely as it is relevant for the broader tech update: we wanted to structure the knowledge-base to give more flexibility around retrieval and maximize the potential of the next generation of AI tools. For years, this knowledge had been scattered across many platforms, including social media platforms like Twitter/X which do not offer compelling solutions to organize and search through bookmarked documents. More importantly, we saw a risk that these platforms could ultimately disappear or, at best, restrict access to historical data.
This threat became very tangible when Twitter/X introduced a cap on the number of tweets that non-paying users could see in any given day, effectively preventing retrieval if the bookmark history exceeds the cap.
During the last 4 months, and for a bit longer really, there have been plenty of opportunities to write about Twitter and Musk. On the negative side of things, a somewhat hypocritical communication on free speech, questionable strategic decisions that impaired user experience, a reckless rebranding using trademarks owned by others or taking-over user names. And let's pretend that the awkward story of the fight with Mark Zuckerberg never happened, this wasn't going to age well anyway. There have been positives too, starting with content monetization for users and to a lesser extent, the roll-out of in-platform payments. Much more important than Musk’s social media platform - which he uses to push and endorse messages with a political dimension-, his satellites network, Starlink, has become critical communication infrastructure globally, giving Musk a direct influence on geopolitical conflicts. This News-Corp-on-steroid model just happened to prove its value coincidentally to Rupert Murdoch’s retirement. Do not worry about Murdoch’s succession : the void has already been filled.
Musk has an entire fan-club covering his successes (mostly) or controversial moves (sometimes) which is really hard if your approach is to take a step-back to analyze: there is always this feeling that it’s too soon to write anything down ; that perspective is lacking. After so many missed opportunities, the main lesson is that never letting the dust settle can be an effective strategy to avoid an “Elongate".
Way too fast
Waiting until the plot completely unfolds is generally recommended. More often than not in the last 4 months, resisting jumping on a keyboard to write about the latest breakthrough was the right call.
When Meta launched its new social media platform, Threads, early July, it wasn't uncommon to read that Twitter/X users would all flee as a credible alternative now existed. Despite some excitement at first, the exodus never materialized. Simply copying Twitter definitely isn’t the right approach. And any claim that the latest copycat would succeed where others have failed should probably just be ignored.
Should this apply to room-temperature superconductors too? In July, Korean physicists claimed to have found their holy grail – something that happens almost as often as Twitter copycats. The material in question that time, LK-99, turned out to NOT be a superconductor but it is fair to say that a lot of people wanted to believe. Both the academic world and the open-science crowd engaged in a wild race to replicate the material, sharing every step on social media with a customary enhancement for sensationalism. There was no room-temperature superconduction in the end, which was probably disappointing for some, but everyone was certainly entertained to watch open-scientists “cook" alien material using tools that very much looked like spare parts of a dismantled meth-lab.

Finally, a team from Stanford and Berkeley posted early August a paper showing that the performance of OpenAi’s best model, GPT-4, had dropped significantly. Although there is mounting evidence that helpfulness as indeed decreased due various initiatives to align the model with certain values, the results of the paper were apparently biased by the grammar of the prompts used for testing which had changed over time. Adjusted for this small change, performance was comparable if not better.
We’ll come back to issues and opportunities of open-science, and on the challenges of assessing AI models performance. But let’s start with a snapshot of the current landscape, and some color on key evolutions since we last published.

Strategic partnerships
Despite the recent decline in performance of OpenAi’s top model, there should be no misunderstanding: the company remains the undisputed leader in the space. And by far. GPT4 is so powerful, so versatile, that the $20/month subscription is a no brainer. OpenAi are pretty secretive about their models but it was revealed over Summer that GPT4 was not one single giant model but is a mixture of 8 expert models that mysteriously work together. Attempts to replicate the mixture of expert set-up (either mixture of models or mixture of LORAs) have reached a proof-of-concept stage but nothing so far seems robust enough to serve millions of users like OpenAi. This goes to show that it is not only about training an incredibly high number of parameters over an even greater number of tokens. Integrating models in a software stack is a real science that OpenAi masters as demonstrated by another tool of theirs, Advanced Data Analysis (formerly known as Code Interpreter), which is arguably even more impressive than GPT4 from a user perspective. The recent release of multimodality (text-to image – DALL-E 3, image-to-text/image-to-code, voice) indicates that the company is not willing to let others catch-up without a fight, even though everything is not a commercial success. For example, ChatGPT plugins or model finetuning do not seem to receive so much traction.
Part of OpenAi’s success can be attributed to its main partner, Microsoft. Not for their technical input in the models, but for their financial backing. Microsoft’s comeback in the spotlight has nothing to do with the recent AI hype. Microsoft have done many things very well for several years now. Satya Nadella leveraged a solid base to establish Microsoft as a critical player in global digital infrastructure, woven into the very fabric of our digital era (Azure, Github, npm, windows and countless software suites). It is virtually impossible today to use consumer technology without interacting with something that’s not directly owned by Microsoft or has been developed using Microsoft products. And recent strategic decisions show that they plan to be even more embedded as AI takes over big parts of users' lives. This Wired article on OpenAi published in September gives interesting background to the Microsoft-OpenAi relationship, confirming our analysis from earlier this year. In September, Microsoft also announced a partnership with Meta so that Bing becomes the default search tool across all Meta apps.
The perspective that users will stop using their web browsers as the main entry point for search is certainly something that should keep Google awake at night, as pointed in the article from April. But Google-Deepmind cannot only focus on defending their footprint in search, they also need to ship Gemini – the AI-suite that would allow them to properly compete with OpenAi on the consumer segment. In all fairness with Google-Deepmind, Bard is a very capable image-to-text model and promising products have been showcased, notably to chat with your documents on GoogleDrive or Gmail. But for the moment, they are not even close to the second place in terms of consumer-facing AI.
The second place belongs to Anthropic, who recently announced a landmark partnership with Amazon. The deal involves contractual arrangements for the use of AWS cloud services and … an up-to $4bn investment in exchange of a minority share in Anthropic’s equity.
Valuations waterfalls
Vertical integration at some level of the AI value chain, and at very high valuations, has been a theme during the last quarter. High valuations rely on the assumptions that AI will ultimately permeate every part of our lives, and that first-movers will create a gap so large that no newcomers will ever be able to catch up. To the question of “when" this will happen, AI-businesses typically answer that we are already in a “slow take-off" dynamic (i.e. the bottom of an S-curve, or of an exponential curve for the most bullish). From where we stand, it looks very early days to tell how things are going to play-out, but there is certainly no “slow take-off" in valuations. To put recent examples in perspective, here is some context : Microsoft have poured at least $13bn into OpenAI since 2019. Last transaction, early 2023, valued the company around $30bn (OpenAi have a “capped-profit" model which impacts valuation, Microsoft reportedly have preferred equity, and OpenAi will use Azure as preferred cloud provider1). It is hard to believe that, based on recent transactions in the sector, OpenAi would not be able to raise capital valuing the company at least three times as high. Another important piece of context: Nvidia is now a 1-trillion-dollar company based on its share price.
Now let’s put all this together:
- Coreweave
The specialized cloud provider, initially focussed on mining crypto currency, successfully pivoted by repurposing their GPU clusters for Generative AI training. In April and May 2023, the company raised c.$400m (Nvidia and Magnetar Capital bought in) based on an EV of $2bn. Then, in August, they secured a $2.3bn-secured credit facility from the likes of Magnetar, Coatue, Blackstone, BlackRock, PIMCO or Carlyle. For someone who has done his entire career in the private capital sector (equity and debt), Coreweave’s funding trajectory is just mind-blowing in many respects, starting with the collateralization of the $2bn+ loan… That said, the company clearly has one very compelling proposition for customers looking to train frontier models on a very rare and extremely powerful cluster of H100 GPUs. Inflection Ai and Mistral Ai (see below) used Coreweave for their first models and are now adamant that the company deserves a seat at the table of top-tier cloud providers for Ai training.
- Cohere
Early June, Toronto-based start-up Cohere raised $270mn from Nvidia amongst others, at a $2.1bn valuation. According to the press release, the company is focused on the business segment, offering data-secure deployment options in companies’ existing cloud environments, customization, and customer support.
- Inflection Ai
Created by Deepmind co-founder Mustafa Suleyman, Inflection is one of the rare start-ups that did not choose the open-source route to attract users. But they are not just any start-up : because of Suleyman, the company does not need to make a name for itself. And because of Suleyman, the company could raise $1.3bn from investors including Microsoft (investors since a $225m round in 2022) and Nvidia. Inflection announced this funding round few weeks after releasing their first model called Pi trained on Coreweave’s cloud. Going forwards, their strategy is to set up a huge GPU cluster to train models. For the time being, Pi has been the sole demonstration of their capabilities and positioning in the space : the “emotionally intelligent" model can be fun to chat with… but definitely not helpful to complete any meaningful task. For this reason, it is unlikely that we’ll cover Pi again in the near future, unless we need to illustrate the contradiction between safety-tuning and helpfulness.
- MistralAi
Set-up by team of ex-Meta and Google-Deepmind engineers, Mistral raised over €100m (for slightly less than 50% of equity) before having even released or trained their first product. The ambition was to train European frontier models, and based on what they have shown since (see below), they seem to know the recipe. The round was led by US VC Lightspeed but a good chunk of the investor-base was made of European investors – largely French – including many individual investors.
- Digital Ocean
In July, the cloud provider acquired another AI-focused cloud business, Paperspace, for $111m… in cash!
- Nomic Ai
The company behind GPT4ALL, a free software ecosystem to train and deploy large language models that run locally on consumer grade CPUs, announced in July a $17m-round led by Coatue and valuing the company at $100m. Nomic Ai was founded in 2022 and had 4 employees when they secured the funding.
- Databricks-MosaicLM
Also in July, Databricks completed the acquisition of MosaicLM for $1.3bn (6x the valuation of previous round). MosaicLM produce open-source LLMs, notably the MPT family (MPT-7B and MPT-30B). Databricks offer Big Data solutions (data warehouses and data lakes) in a unified platform which is used by enterprise-type clients globally. Earlier this year, they had released their own open-source model, Dolly.
- HuggingFace
In August, HuggingFace announced a funding round of $235m including Nvidia and Google and valuing the company at $4.5bn. HuggingFace is the hub for models, datasets and all types of resources for the opensource community. HuggingFace has been first-mover in the space and have built a significant gap over peers thought network effect. They are likely to remain the leader in the space.
These incredible numbers bring us back to a not-too-distant past, when metaverse and NFT companies raised millions based on multi-billion valuations. Many people these days are convinced that AI is just another bubble that will burst within 12 months. We do not necessarily share that view, based on work we had done on NFTs in the past2, but it may well be the case that this time is no different. However, if you are concerned that funding will dry up soon, you need to consider one thing: given where financial markets are heading right now, AI may also be the only sector where asset managers are willing to deploy capital in 12 months from now. And a race-to-safe-heaven is a dynamic that is generally NOT synonymous of a drop in funding.
The Open Source Nebula
Although the top of the value chain is extremely concentrated (infrastructure players, manufacturers of machines to build chips, chips manufacturers…) the landscape at the bottom, where smaller models are trained and finetuned, is very fragmented. The unofficial term to describe this ecosystem is the "model zoo" but "nebula" seems a more appropriate analogy: small particles seem to travel freely in all directions and, as some coalesce, other particles start to gravitate around the clumps. In practice, new techniques emerge and opportunistic collaborations between players who iterate extremely quickly – sometimes individuals – can lead to one-off releases, which in turn constitute a base for finetuning further down the line. This nebula will undoubtedly give birth to stars, potentially galaxies. But most of the nascent clumps will just break apart when the next big thing flies by.
At the center of the cloud of dust, “open" models act as primitive stars orchestrating the movement around them for a while, until they are outshone by a more recent ones. Here, “open" is more likely to mean “open-weights" or "freeware" rather than truly “open-source" and the distinction is important as the level of openness can materially impair your ability to use the model or its outputs at lower stages of the value chain. For example, OpenAi’s or Anthropic's terms of service prevent the use of the model outputs to build synthetic datasets and subsequently train other models (a process called distillation). Even for models widely presented as “open" there can be subtle nuances that should not be ignored. This article from Alessio Fanelli is a good resource to understand the full spectrum of openness in Ai.
The leak of the weights of the original Llama models kickstarted the finetuning wave in February/March this year, but the resulting models were of limited use due to the lack of licence. The gap in the market was filled by players like the Abu Dhabi-backed Technology Innovation Institute (Falcon models) or private players like StabilityAi or MosaicLM – MPT-7b was on of the base models of reference until July. That’s when Meta released their Llama2 models with a very permissive licence, and as a result, the Llama-2 suite immediately became the go-to base LLMs.

I think Llama-2 will dramatically boost multimodal AI and robotics research. These fields need more than just blackbox access to an API. So far, we have to convert the complex sensory signals (video, audio, 3D perception) to text description and then feed to an LLM, which is awkward and leads to huge information loss. It'd be much more effective to graft sensory modules directly on a strong LLM backbone.
Jim Fan, research scientist at NVIDIA AI
Although Llama-2 models remain instrumental for the open-source community, the latest Qwen models (Alibaba) and Mistral seem to have set new standards for small models at the end of September.
Open-source developers, probably intrigued by Mistral’s release strategy – making the weights available via torrent, the process used to leak the original Llama weights in February –, rushed to finetune the models and enhance their capabilities. For the Mistral and Qwen models, one aspect that was particularly praised by developers was their rawness, i.e. the absence of safety-tuning that generally impacts helpfulness negatively. Raw models are not fit for consumer usage, but they can be more easily tuned and integrated in data pipelines. Right now, the direction of travel is a specialization of the open-source world with institutions that focus on the heavy-lifting to deliver raw-models, and delegate the finetuning to smaller players leveraging high-quality datasets. The cost of training foundation models means that the sustainability of the aforementioned set-up is currently questionable. But costs should drop (if training data remains largely free), and in the meantime, some of the smaller players showcase the extent of their capabilities.
It is realistically impossible to cover everyone and all models in the open-source space (this should give you an idea of why). If you want monitor this yourself, just bet on people’s desire to brag : each time a new model is trending for a given category (by size, modality, use-case…), check the release paper and see what models it is compared to. Some of the best open-source models out there were produced by independent players, sometimes individuals or groups of individuals that team-up for one-off projects. Notable ones include WizardLM, Nous Research, Jon Durbin (individual behind airoboros), AlignmentLab Ai. Tom Jobbins (TheBloke) also deserves a mention here as he single-handedly quantizes most LLMs so that users can run them on consumer hardware.

If you are willing to spend enough time on HuggingFace, you are likely to find many high-quality models issued by parties who do not even have a website. But don’t be mistaken, it does not mean that they operate under everyone’s radar. The most prominent ones benefit from grants for compute from VC firms and/or are unofficially backed by Big Tech. WizardLM, for one, is rumored to be a shadow lab for Microsoft.
An underrated benefit of open-science is that independent researchers are generally quick to benchmark models, challenging sensational claims of superior performance and identifying issues. A common issue is that models are trained on the evaluation datasets so they score very high on benchmarks but it is not indicative of intrinsic generalization capabilities. Recent examples of this issue have been Phi-1.5 (Microsoft Research applying their "Textbooks are all you need" approach) or the NewHope model from SLAM group who initially claimed that their model was performing on par with GPT-4.


The LK-99 superconductor clearly highlighted the limitations of open-science but, in computer science, contributions of independent researchers can be extremely valuable. It is not unusual these days to see a social media post quoted in a research paper. For example, regarding context window extension, this paper from Nous Research, EleutherAI and University of Geneva quoted Reddit user Block97, and Meta quoted another "anon", kaiokendev, in this paper. Social networks, which includes to Github in context of computer science, are generally good places to brainstorm, test ideas and solve issues. Open science has downsides though, as virtually anyone feels entitled to “publish" research papers - which are never peer-reviewed - on Arxiv even when a mere blog post could have more impact. For that reason, the scientific community is divided on the subject. But from an outsider's point of view, the benefits probably outweigh the downsides for consumer-level AI products.
So far, we have mentioned Alibaba's Qwen or Abu Dhabi’s Falcon models but we have mainly considered AI and Tech as part of a globalized market, ignoring country borders or regional specificities. However countries and regions matter… a lot. They matter for the geopolitical implications of the Tech value chain, they matter for regulations, they matter for what happens under the hood of the models. We’ll cover all this in our next article.
We have also mostly focused on AI from the angle of language models, which only constitute a fraction of the AI-space. And not everything needs to be AI-powered. We plan to tell you more about the rest in a future post, from vision to virtual reality to brain-computer-interface. In the meantime, you can enjoy a selection of recent demos to give you an idea of real use-cases for AI across the different, not mutually-exclusive, modalities.
Video editing
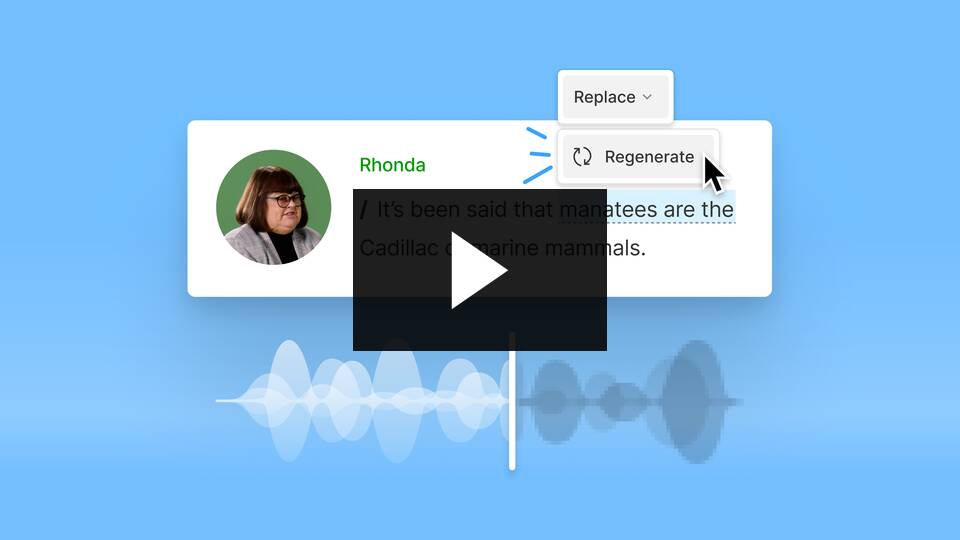
Translation
Creativity and design with Stable Diffusion and ControlNet




Knowledge graphs
Sketch-to-code






