Despite ChatGPT (OpenAI) boasting 200 million weekly users and Meta's models reaching 400 million users, consumer-oriented AI is still in its infancy. As with any sector at this stage of development, time is needed to establish standards and market practices. Industry players, in search of viable business models or a mere validation of 'product-market fit', are not just innovating in terms of products or services: they're also getting creative with their commercial practices. Even if it means potentially misleading customers.
When selling “intelligence”, it's best to remain vague around the definition of the service provided. The fact that clients are willing to enter contractual relationships without clear definitions proves that they themselves don't know exactly what they want to buy. As long as there's 'AI'... the box seems checked.
The asymmetry between clients and providers should diminish over time pursuant to usual market dynamics. But in the meantime, it seems all tactics are fair game to attract customers.
The challenge is twofold:
- Short-term: To display impressive figures in marketing presentations for upcoming funding rounds. These figures never measure satisfaction*, but simply quantities of customers, through metrics that may not fairly represent current or future economic reality. At worst, it's just a number of sign-ups or active users; at best, projected revenue based on various hypotheses.
- Medium-term: To quickly establish themselves as market-leader and hope to acquire such a large market share that it becomes impossible for newcomers to displace them. However, unlike Web 2.0, it's not the 'network effect' that's expected to lead to an oligopolistic market in AI**. Instead, industry players bet on a 'first-mover advantage' linked to the colossal investments required to develop models***. This is, in fact, the main justification given for the fundraising mentioned in the previous point; with the notable exception of Meta, which develops its models using its own resources.
Fortunately for the entire ecosystem, these days, AI is a selling point on its own. Curious nerds willingly pay to verify if the newest product truly brings us closer to artificial general intelligence but, above all, AI sells a lot of consulting missions and conferences aimed at identifying its opportunities rather than its limitations.
AI sells dreams to potential users seeking productivity gains as much as to entrepreneurs who see themselves becoming millionaires overnight - at least on paper - in the event of successful fundraising. For the latter, the motivation isn't necessarily financial; it might simply be about being in the spotlight, having the illusion of being part of the exclusive circle of highly glorified Tech entrepreneurs. The dreams of entrepreneurs encourage questionable commercial practices; the dreams of users allow them.
Beyond the Pitch?
An assessment of commercial practices in the AI industry must begin with those cases where the dream doesn't concern AI's potential, but the very existence of the product or service.
It wouldn't be fair to blame entrepreneurs for the ambition and optimism that is necessary in any entrepreneurial venture. Overselling is part of the game; it's a way to secure resources and to buy time to achieve very real objectives. In OpenAI's case, many announcements have been made, and it appears they have indeed developed impressive models for video (SORA) and for advanced voice interactions, but they're not yet ready for large-scale deployment. However, in some cases, exaggeration in pitches is outright deception and bad faith, with unclear motivations.
Here are some examples from the past 12 months:
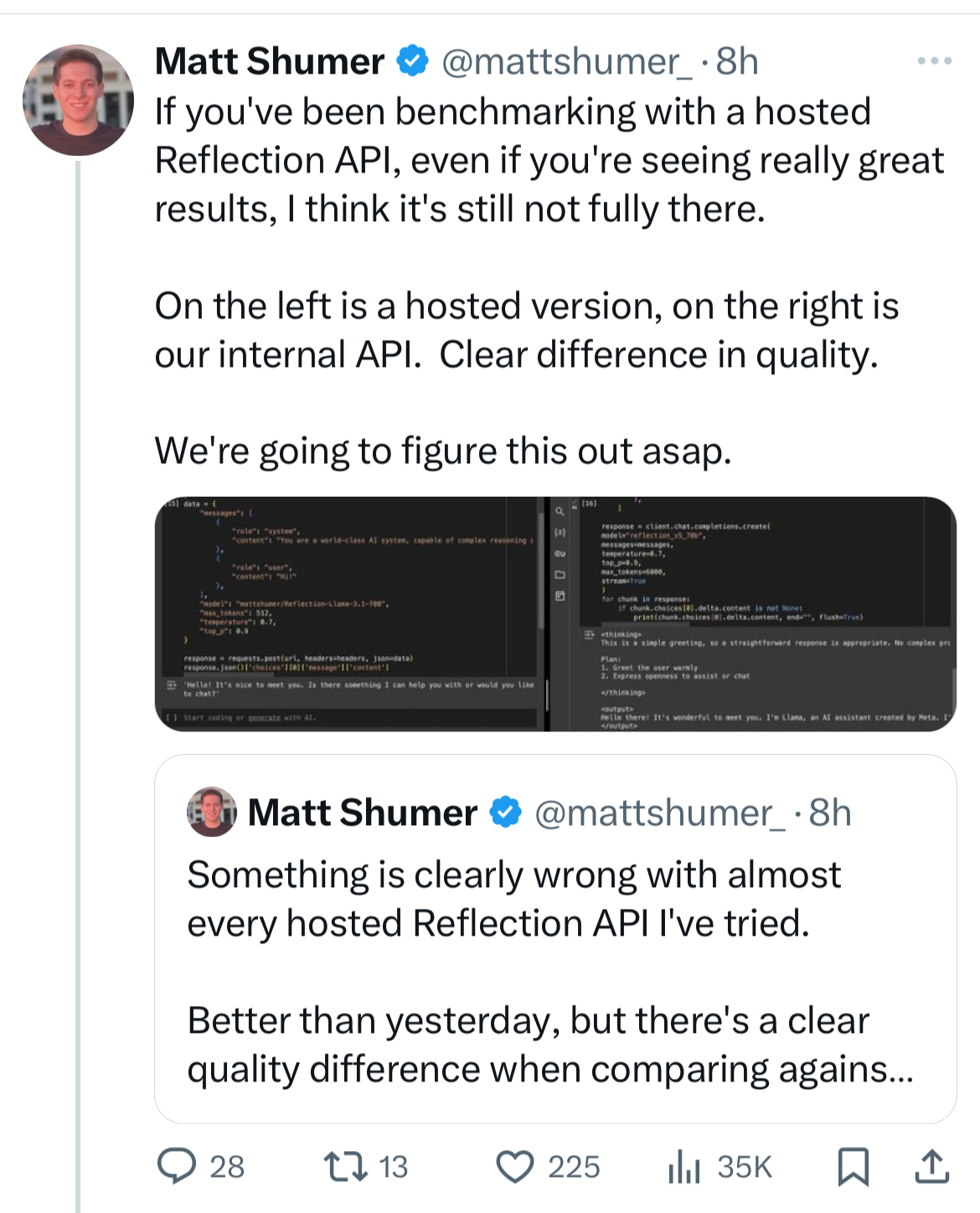
- In Q4 of 2023, a startup called Rabbit announced funding rounds amounting to $30m to reinvent the smartphone by leveraging new artificial intelligence technologies. The ambition to build an intelligent device with an operating system that could activate services corresponding to user requests without a need for bespoke integrations with apps like with APIs. This unique interface was supposed to be powered by a Large Action Model, a new class of model developed by Rabbit. After an initial presentation in January 2024, Rabbit announced having received nearly 100k pre-orders for the $200-device. Three months later, deliveries began, and it quickly became apparent that the 'Large Action Model' was, in fact, merely a marketing concept. In practice, the operating system accessed a LLM (apparently from OpenAI) via an API and subsequently attempted to connect to applications based on its interpretation of the model's responses (after asking for a username and password, which are passed over the network in an unsecured way). Even though the solution was 'low tech', the success rate reported by users seemed extremely low...
- Humane is another startup whose mission was to equip you with an intelligent gadget to replace your smartphone. In March 2023, the startup, led by former Apple designers, announced raising $100 million of fresh equity, bringing the cumulative amount of its funding rounds to $230 million. The product wasn't unveiled until November 2023 : a small device called Ai Pin, relying on OpenAI's models, and promising to cram the functionalities of all your phone's apps in a screenless device. The device itself was sold for $700, with a necessary $24 monthly subscription.
“It’s so bad that it’s kind of distracting to understand what the point of the device is" - Marques Bownlee
“After many days of testing, the one and only thing I can truly rely on the AI Pin to do is tell me the time" - The Verge
A month ago, The Verge revealed that the number of devices returned by customers exceeded monthly sales, and Humane had no choice but to discard them. Furthermore, key employees had reportedly left the company.
- Founded by Mustafa Suleyman, co-founder of DeepMind,
InflectionAI is one of the few AI Labs producing foundation models that didn't choose the open-source route to attract users. But this wasn't just another startup, as thanks to Suleyman - also the author of a bestseller recommending strict control of AI tools - the company didn't need to make a name for itself.
Mid-2023, the startup was able to raise $1.3 billion from investors including Microsoft (an investor since a $225m-funding-round in 2022) and Nvidia. Inflection announced this round a few weeks after releasing its first model called Pi. Their long-term strategy was to set up a massive, proprietary GPU cluster to train their models. The first Pi model was meant to demonstrate Inflection's capabilities and their positioning in the ecosystem: an 'emotionally intelligent' artificial intelligence. However, everyone who tried it seemed to agree that this AI was intelligent in name only.
In March 2024, less than a year after the funding round, Microsoft hired away Suleyman and many of Inflection's engineers, compensating other investors to the tune of $650m. The official version is that Microsoft paid for access to Inflection's models. And this is probably what history will remember about Suleyman, who now leads Microsoft AI.
While the main victims are VC funds and established Tech players with cash to spare, end users - those who buy the equipment, as in the cases of Humane or Rabbit - may feel deceived. For LLMs, it's not so much the end-users but the developers who may be frustrated if they spent time building solutions around an API and purchasing credits for a service they won't use. Fortunately, in Inflection's case, no developer likely wasted time or money given how useless the model was.
Meaningless benchmarks
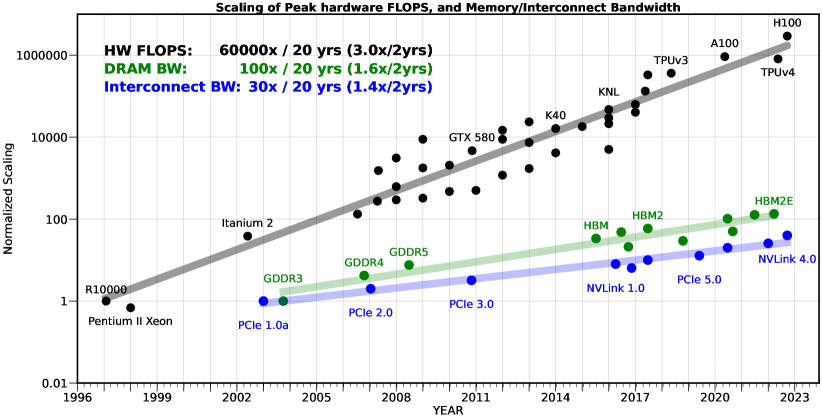
To convince customers, you need to show that you're good. And to gain market share, you need to show that you're better than others. However, clients often lack the technical background to evaluate performance or the time to compare different providers. In the rare cases where users have both the technical skills and the time, money becomes a significant obstacle as they need to reproduce tests across several paid APIs and/or rent GPUs to run public models in the cloud. And to validate the responses, they might even use... another LLM. Properly running a benchmark potentially represents millions of queries, and the bill can be hefty.
Against this backdrop, public evaluation sets have been developed so that everyone can obtain a score for a model using a predefined method****, allowing models to be compared between them without having to test all models each time. Since these evaluation sets are by definition public, the evaluation data ends up in the training sets of the models, either because someone couldn't resist the temptation to put them there, or because they were automatically scraped from the internet and no one bothered to filter the corpus. Everyone benefits from this so all models are 'contaminated' to varying degrees. This explains the observed saturation of benchmarks, and for this reason, it's not fair to claim that the latest OpenAI models are better than previous ones or that Microsoft's smaller models rival the large models of Meta or Mistral.


Another widespread practice for gaming evaluations is the use of different prompting techniques. This involves taking as a reference the score of a competing model obtained through a simple prompt (a single question for an answer - 0-shot) but to pass through your own model more elaborate prompts. For example, one can provide examples of good answers in the prompt ('few-shots') or ask the model to explain its reasoning steps or strategy to obtain the answer (for instance, through the 'chain of thoughts' strategy, aka 'CoT'). A good prompt can significantly increase a model's performance, but the resulting score doesn't reflect performance relative to other models if the rest of the leaderboard isn't subjected to evaluation using the same technique. Another problem with using different techniques is that a simple prompt requires fewer input and output tokens than elaborate techniques, but the relative cost of different approaches is never made explicit.
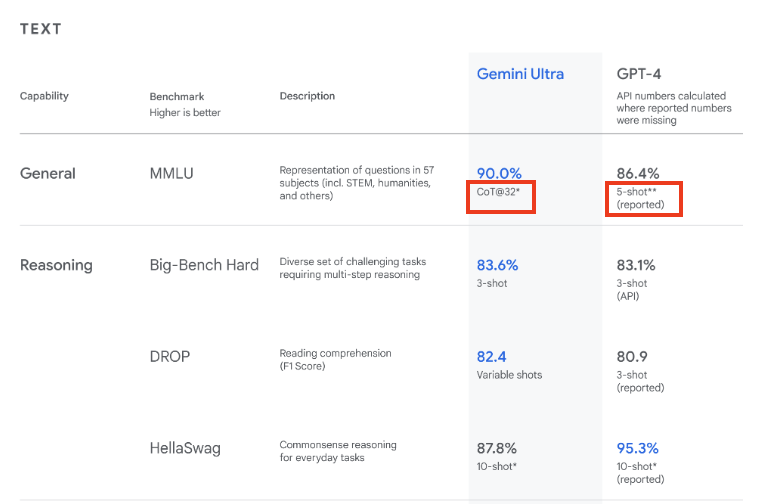

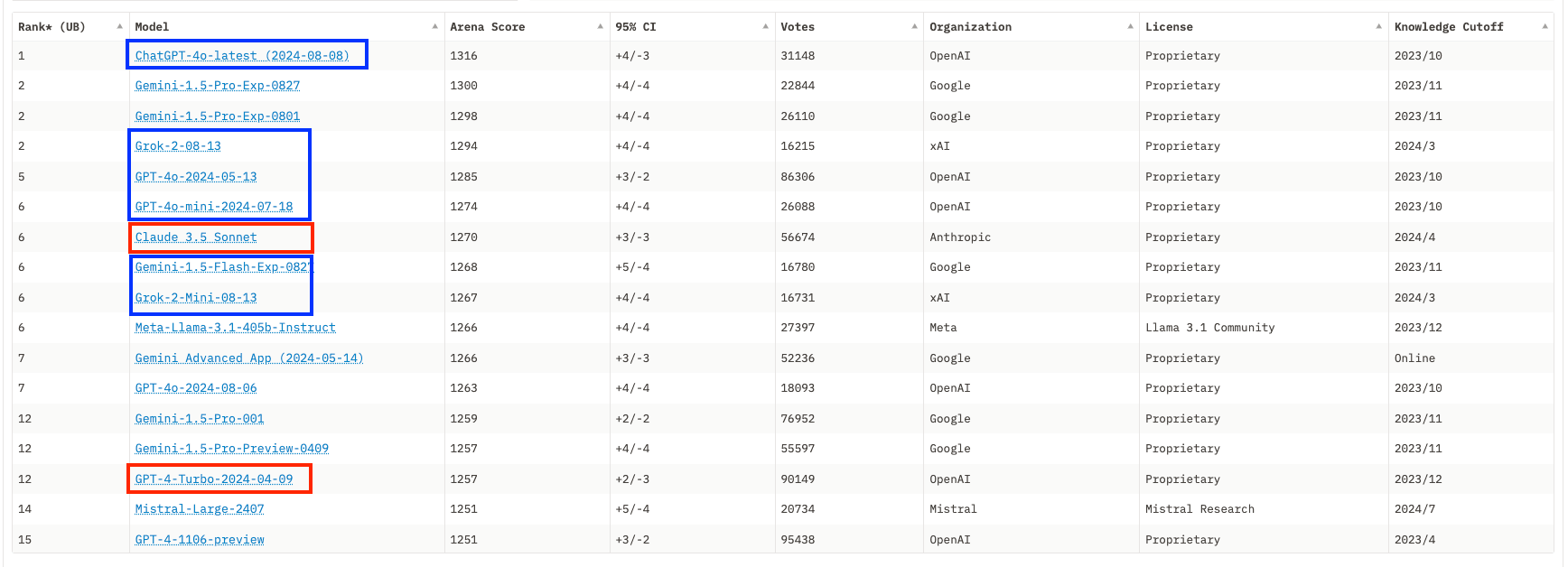
While the general public is still unaware that benchmarks have lost all meaning and are now only valuable for Marketing departments, the user community has organized itself to implement alternative evaluations based on ELO scores. In practice, users compare the responses of two different models to the same prompt and vote for the better one. A relative score can thus be defined, and the LMSYS Arena leaderboard was long considered the reference in the field. However, those who saw these ELO scores as a panacea forgot that the core business of AI labs is to identify trends in an ocean of unstructured data and align their model to fit the curves. While it's not possible for an ELO score to saturate, it has been clear for several months that market leaders have well identified the preferences of LMSYS users (for example, in terms of response format or length), and most new models seem to produce ELO scores with no correlation to the actual capabilities for uses other than LMSYS scoring. The latest models from OpenAI or xAI hardly justify in practice the scores that place them at the top of the leaderboard.
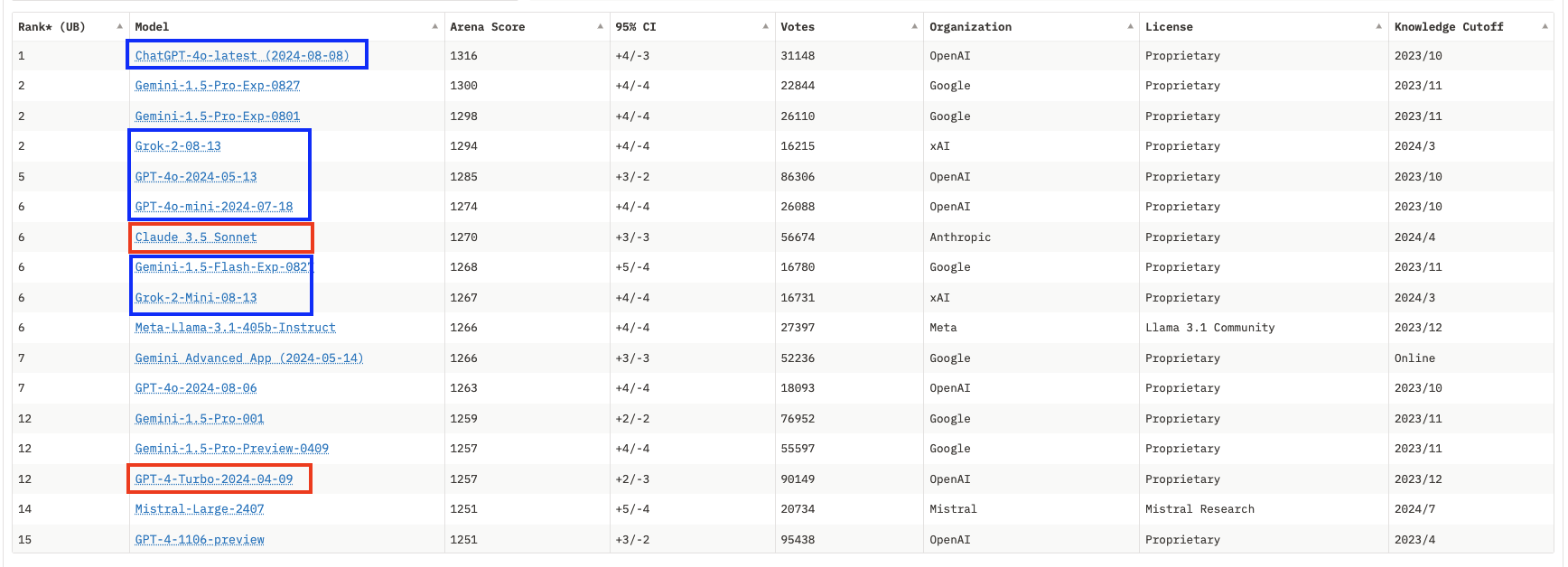
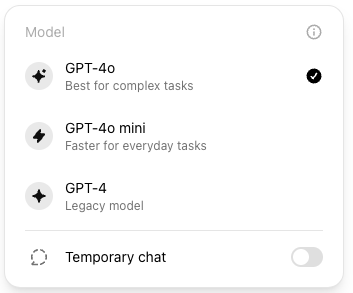
For model vendors, it's not just about proving they're the best to attract new customers, but also about pushing existing customers to switch to smaller models that are faster and cheaper to serve. OpenAI recently defined GPT4o as the default model, emphasizing in their communication the model's better performance (implicitly: according to evaluations), which doesn't hold true in practice: GPT4-Turbo, now dubbed ‘legacy’ model, remains better, but now requires an extra step to access. If you're a simple user paying a fixed monthly subscription, the cost to OpenAI or Anthropic matters little to you; using a cheaper model only impacts the vendor's bottom line, and it's fair game if you are satisfied with the service.
But if you're processing large volumes of data or producing synthetic data, you necessarily go through the API and pay for the tokens you consume and you want value for your money. Price and throughput, i.e., the number of tokens that enter the model (prompt) and exit (response) each second, are actually the main arguments for using APIs rather than open-source models locally. Few users have the infrastructure to serve public models comparable to those of OpenAI, Anthropic (Claude), or Google (Gemini), let alone with similar throughput. But the gap in the market was quickly filled as providers emerged to host the best open-source models and provide access via an API. Competition between these players is based on both throughput and price: tokens are presumably sold at a loss - in a way subsidized by VC funds - with a million tokens costing only a few cents**********. No one really reveals their recipe for serving models at scale, but it seems that here too, they attract customers by displaying sometimes misleading figures.
To understand this, we need to go back to the evaluation score,- public test, or ELO score,- which cements an open-source model's position in the hierarchy. A model rivaling closed models according to evaluations - provided it's properly configured by the provider**** - is a decisive selling point. In the case of Meta's largest model, Llama-3.1-405B, many providers quickly ****** announced they could serve the model at extremely competitive prices and throughput compared to closed models. One of the keys to serving this model economically is to reduce the precision of the model's parameters.
The concept of numeric precision in computing isn't entirely trivial, but you can imagine that each 'weight' of the model is a number that takes up more space, in bits, if the precision is high. The lower the precision, the faster the computation and the cheaper the inference, but, as the name suggests, the less precise the calculations, which impacts performance. In the case of Llama-3.1-405B, almost all providers initially served the model with lower precision (FP8, for 8 bits or 1 byte) than that with which the evaluations were carried out by Meta (bf16, 16 bits). We may one day get quantized versions (with reduced precision) without performance degradation, but this is not yet the case. While few users could notice the difference, one had to read between the lines to identify the dichotomy between the service sold and the performance delivered.
This information asymmetry also suggests that some providers serve even more quantized versions (which is typically the case for local inference) without making it explicit. It's also not unreasonable to think that providers, regardless of who they are (closed model APIs or open-source model hosts), could switch between different model versions to handle demand spikes. There's no way to guarantee that requests are routed to a specific model, and some have sometimes had to defend themselves against accusations of changing the underlying model without notifying clients. In any case, building a solution around a specific model and hoping to have access to it in the long term seems to be a risky strategy.

Tools or systems?
When using a generative AI tool via a browser or API, the need for clarity on the service provided goes beyond the simple question of which model the prompt is routed to. Regarding the framing of responses by the provider itself, the lack of transparency is often problematic. There are several ways to interfere to promote or censor certain informations that the model might generate:
- first, during the post-training and reinforcement phases that follow the model's training. These phases are important to allow users to interact naturally with the models, but they also serve to align models with certain values. This is, for example, what led to the controversy surrounding Google's image generation model, which had been so trained to promote diversity that it under-represented white people (and that's an understatement).
 Source : BBC
Source : BBC
- by altering the user's prompt, typically by pre-pending a system prompt defined by the provider to automatically add instructions on how to handle requests. Except in Anthropic's case, these system prompts are rarely public and are only revealed by the LLMs themselves when users manage to extract this information from them*******. While it might be tempting to praise Anthropic for their transparency, it was recently revealed that sentences were added to all API requests, which they had never disclosed.
- Finally, it's possible to guide the model’s output through control vectors that directly change how neurons are activated. The method has proven effective experimentally, but it's unclear if it's applied in production. Research and advances in interpretability suggest a wider use of these control vectors in the future.
Some institutions feel that they have the responsibility of making their models simulate values by prohibiting answers to certain questions. While the intention may seem laudable at first glance, it is no different from the Chinese Communist Party's policy of ensuring that publicly accessible models 'promote socialist values'. (literally, it’s in the law!).
Whose data is used for what?
Finally, a critical aspect of the commercial relationship between LLM providers and clients is the use of data. The question is relevant for both the data submitted by users and the data that models spit out. Model developers have incentives to both collect your data to train their models (at best it's allowed by default, at worst it's unclear) and to prohibit you from using the data that comes out of the model for commercial purposes (or even to ensure that the data produced by the model belongs to them).
Anyone who works extensively with LLMs as assistants knows that, very quickly, the line between user data and model data is blurred, as it's an iterative process where both human and machine contribute, each copying and modifying the other's suggestions. Terms of use and data protection policies don't really work in practice. This issue is probably not a major concern for individual users, but a company will certainly be more sensitive to the integration of proprietary data into models training sets. Uncertainties about the ownership of data coming out of the model also constitute a sword Damocles if the relationship with the provider were to deteriorate. As Legal departments get involved, they should use the occasion to check who is responsible if a model leaks sensitive information : as in the case of system prompts supposed to be confidential, LLMs have a very hard time keeping secret******* any information that they have access to...