The benefits of a less-frequent format are twofold: more time to digest the news-flow and more time to play around. When you build something useless for fun, you always end-up spending more time than initially intended. This pushes to filter out less-important subjects and park others for later. However some interesting themes need to be covered... before they become irrelevant.
Autonomous Robots
If you are old enough, you have probably heard many times that everyone will “soon” be assisted by autonomous robots in their day-to-day lives … and have stopped believing it. Given everyone’s poor track record at predicting this, we ought to be cautious when announcing that autonomous robots are now within touching distance.
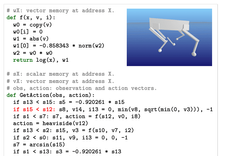
Many of such projects are still at experimental stage, as illustrated by the adorable football humanoids presented by Google/Deepmind last week. A robot-filled future felt more real when RATP (transport operator for the Greater Paris area) showcased Boston Dynamic’s Spot robot-dog for maintenance operations. Spot is also expected to be rolled out by The New York Police Department which re-launched the initiative two years after a first attempt that was not particularly well received by the population. If you think that Spot alone does not give a clear line of sight on autonomous robots deployment, you may be convinced by one of the numerous videos popping-up on social media from users travelling in driverless taxis in San Francisco.
It does not mean that the technology is commercially viable yet – it wouldn’t be a first in Silicon Valley – yet the timeline has seemingly accelerated.

source: bostondynamics.com
Neural Radiance Fields
You don’t need to be very old to remember being told that everyone will “soon” spend a good amount of their awake time in a metaverse… a statement that would likely attract mockery today. A major friction point for user experience is the awkwardness of interactions with other individuals’ avatars. The social equation may require a lot more fine-tuning – and may never be cracked -, but the technical hurdles to create virtual worlds at scale fall one by one.
Neural Radiance Fields (NeRF) are one of the promising technologies that leverage AI to generate 3D objects / scenes from 2D images. A quick look at Jonathan Barron’s page (author of this paper) gives a pretty good idea of immediate commercial applications. And opportunities in gaming seem infinite. See Matthias Niessner's balanced overview of recent progress made in the field and challenges yet to overcome.
@hoodwinkedfool What the other side looks like #hostilecounty #crackinthesky #liminalspaces #backrooms #mirrorworld #liminalcore #weirdcore #liminalspacetiktok #portals
♬ original sound - Hoodwinkedfool
OpenAi’s hype : f(t)=sin(t)+1
The AI-hype probably reached a peak in March after OpenAi successively announced GPT-4 and the ChatGPT-Plugins. The company managed the descent in engine braking mode, either because what they announced was not entirely ready or because of the unease it generated among the intelligentsia (in practice few users have tested these tools ; the feedback was overwhelmingly positive for GPT-4, lukewarm at best for plugins). During this period, OpenAi seemed focused on "castrating" its more powerful model and mainly communicated on a focus on GPT-4 as opposed to developing the next version.
That was until last week, when OpenAi released the code interpreter and created a new wave of hype. They started talking about GPT-5 again, and future growth plans.
The code interpreter basically writes and executes code, which allows the model to do … anything. Including handling files, creating and editing media (image, video, audio), manipulating data, identifying issues, performing complex analyses, writing summaries. Based on examples provided by third-parties, results are mind-blowing, and apparently reliable. As Ethan Mollick put it in this brilliant article: it is starting to get strange. It certainly feels strange to consider that everything I did in the first couple of years of my career as a financial analyst (including some mistakes corrected by someone else) could now be done in a week.

AI Alignment
Anyone who has followed the AI safety debate from its inception may have noticed that fame has gone to the heads of some of the early contributors. As the quality of the debate decreased materially on both ends, other members of the AI-community stepped in, including pioneers who played instrumental roles on one or several branches of the LLM family tree.


Source : Michael Trazzi
Geoffrey Hinton who received the Turing Award in 2018 (alongside Yann le Cun) recently opened-up in the New-York Time about his concerns after he retired from Google. Paul Christiano, who runs the Alignment Research Center that worked on the GPT-4 safety card and previously ran the language model alignment team at OpenAi, went as far as associating directional probabilities to his views on doom. The focus on a "god-like" AI takeover scenario sometimes feels odd, at least relatively to the trivial risks of humans using AI to harm other humans. But maybe it's part of the 54% "good future" scenario as humans would just be humans as before. There is one sure thing : optimists and pessimists will have very different reads of his article.
The open source route
As the AI market matures, one would expect a certain form of segmentation and the OpenAI-Microsoft tandem have started positioning their chips on the business segment. Not only by offering the best solutions today, but also by communicating heavily on data security and privacy (even though we still doubt that an LLM interacting with the open internet can keep anything secret in practice). We can already predict that these two will end-up stepping on each others toes, but Microsoft's financial support in context of OpenAi's $540m loss last year, should help preventing tensions in the short term.

Even though GPT-4 looks omnipotent by our current standards, market segmentation will likely imply a large number of LLMs - if LLMs remain the relevant AI-technology- potentially tailored for specific segments. It’s hard to believe at this stage that open-source models will truly compete with state-of-the-art models but so much power and versatility may not be necessary after all… and many companies are willing to give it a go as there is no better time to surf the AI-hype wave and raise capital.
Last time, we talked about Databrick's Dolly 2.0. Since then Repl.it’s huge ambitions, on the back of a successful funding round valuing the company over $1bn+, have started to materialize with a first release : an open-source code-focused model called replit-code-v1-3B. StabilityAI dropped 3B and 7B open-source language models called Stable-LM. MosaicML also introduced a promising model with MPT-7B.
An interesting takeaway from Repl.it's plans revealed during a recent developer day, is that language models seem to learn logic better if they are trained on code than if they are trained on text only (GPT3.5 was also a fine-tuned version of a pure-code model).
In a previous article, we explained that, if you think that your product will eventually become a commodity, you want to be the platform not the product. And the first movers are more likely to prevail, even more so if they are well-capitalised. The odds are therefore not in favor of open source solutions. But if you need to be convinced that less-powerful, open-source models can be relevant, have a look at this leaked internal document from a Google employee (apparently more of an internal blog than actual material for strategic discussion).
At the beginning of March, the open source community got their hands on their first really capable foundation model, as Meta's LLaMa was leaked to the public. It had no instruction or conversation tuning, and no RLHF [...] Here we are, barely a month later, and there are variants with instruction tuning, quantization, quality improvements, human evals, multimodality, RLHF, etc, etc, many of which build on each other.
Most importantly, they have solved the scaling problem to the extent that anyone can tinker. Many of the new ideas are from ordinary people. The barrier to entry for training and experimentation has dropped from the total output of a major research organization to one person, an evening and a beefy laptop.
Semianalysis.com - leaked internal document from Google : "we have no moat, and neither does OpenAI"
The document touches on a very interesting point : Meta have accidentally put themselves in a position where "ordinary" people build on their models and the results are considered significant enough by the AI-community to create dependencies and therefore high switching costs for developers. In a sense, Meta's has a "moat"; despite not being [invited?] to discuss AI safety at the White House on May 4th.
Specific context
One of the key techniques underpinning open-source models is the Low-Rank Adaptation (LoRA) and it’s particularly promising in the long run as it allows to further fine-tune models at low-cost to incorporate more recent information. This allows to update models in near-real time, and more importantly to consider cultural cycles which alleviate the issue of setting the mainstream view in stone.
These biases are not so obvious with language tools but, if you type "woman" without context in an image generation tool, you will find that the output by default differs significantly from what a randomly-selected woman would look like in reality. The models are built and trained to deliver this specific bias, i.e. what people want to see instead of the reality, so there is little to argue about it. But it's important to appreciate that these biases exist because they may not be relevant in 5 years and the models would need to evolve in that case.
One can also envisage that cultural differences and changes will ultimately be accounted for at an individual level if models can remember the “context” of a user – that is, their personal profile based on previous interactions with the model. For the moment, the context length is limited but more profound changes in the underlying LLM architecture could increase recurrent memory to over 1 million tokens as described recently in this paper. Let's see if anyone is willing to risk switching architecture when the industry is all-in on transformers.
Whilst everyone is looking away, Apple becomes a financial institution
Outside AI, one of the recent developments in Tech is Apple starting to pay interests on saving accounts. The interest rate of 4.15% does not seem extremely competitive but trust in the brand and easy customer journey were enough to attract $1bn in deposits in just a week.
This happens coincidentally with a deposit flight in many US banks: regional banks are bleeding money to a point where the stability of the banking system is questioned. The term “too-big-to-fail” comes back often in the news these days without a precise definition of what it means. Goldman Sachs and Morgan Stanley are undoubtedly in that category with, respectively, $375bn and $347bn in deposits most recently as per this Reuters article. And here is a fun fact: Microsoft, Amazon, Google, Apple and Meta had together more cash and cash-equivalents on balance sheet at the end of last fiscal year than these two “too-big-to-fail” banks had deposits.